





Everything You Need To Know About Robots.txt

Christian Velitchkov


Technology
We are talking about robots.txt and how to make these files work for your site. With robots.txt files, you are in charge of what search engines crawl on your site which can generate positive changes.
You will learn what they are, how to use them, and how to make sure you are doing it right! If you want to rank higher, you will want to learn more about robots.txt.
Related Link: The Ultimate Beginners Guide To Showing Up On The First Page Of Google
What Is A Robots.txt File?
Simply put, robots.txt files either allow or block crawlers from accessing portions of your website.
When searching for a specific topic on a search engine, some bots are dispersed to find the information you have searched for. The goal is for searchers to land on your site, but there are portions of your website you may not want to be crawled. That is where robots.txt files come in.
A road map was designed for bots specifically to follow, and typically the bots do not stray from the road map.
Robots.txt files either allow or block crawlers from accessing portions of your website. They do this through directives that tell each search engine if they can or cannot search a page. As with anything, there are acceptions to the rule, but these directives work very well and the application of these files can be very helpful for your SEO.
Where Are Robots.txt Files?
If you’re unsure of where to look for and edit your robots.txt files, you will be happy to know that they are relatively easy to locate.
Robots.txt files are stored in your root directory. Simply type in the base URL of the webpage the “/robots.txt.” This will take you to the plain-text page where you can view and edit all of the robots.txt files on your website.
Don’t Have One?
At this point, you may be asking yourself why you need robots.txt files? Are they necessary?
Maybe you feel like you’ve been promoting your blog well, and you don’t need extra help.
The truth if, implementing robots.txt files can be beneficial for your website’s SEO in multiple ways.
There may be sensitive information you don’t want on a SERP, or maybe the page just isn’t of value. Whatever the reason, using a robots.txt file to manage where your website is crawled is something all sites need to consider. In fact, it is recommended by Google that websites include these files.
As previously mentioned, robots.txt files block specific parts of your site from being crawled. These files can be modified to not allow certain crawlers from finding and indexing your page. If there are too many third parties crawling a website, it can slow down your site.
Related Link: Best WordPress SEO Plugins
Create Your Own
One of the beautiful things about a robots.txt file is its simplicity to create. You may have noticed you don’t have any on your site and want to create them. It’s a relatively simple task that can be done on a basic text editor.
You will need to create a new file on a simple text editor (think Notepad) and save it as “robots’txt.”
Next, you will need to access your site’s root directory. That can be done by logging in to your cPanel and finding the public_html folder. Once you locate that, you can drag in your Notepad file.
Lastly, you will need to set the permissions for the file. As the owner, you want all of the access to the file, and you want to block all other parties from having full access. You want to be able to “read,” “write,” and “execute” the files as the owner.
User-Agents
When you identify a user-agent individually, the bot crawling your site will be attracted to the lines that mention them.
User-Agents sounds way more complicated than they are. Essentially, they are just how each search engine identifies itself. If you go down the rabbit-hole, you will find hundreds of user-agents, but there are only a handful that are useful for SEO practices.
What a robots.txt file does with user-agents is it tells them specifically what to do when it lands on your page. For example, you can “allow” or “disallow” user-agents from crawling your page.
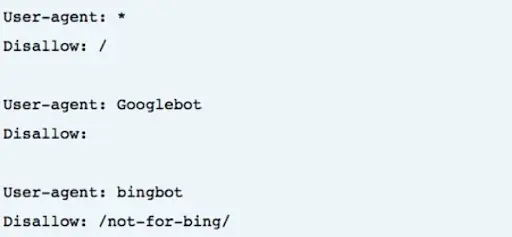
If you would like to address all user-agents at once, you can put a “*” symbol, which is called a wildcard. This is a great way to address one function across the board.
Directives
Directives are the directions that you write into your robots.txt for each user-agent to follow when it crawls your page. Essentially you add directives to inform crawlers on how to interact with your page. Whether you want to block them from accessing a page entirely or how to interact with the page once it does open it.
When creating directives, be careful of making contradictory commands.
Search engines will skip over a directive if there is no clear path for them to take.
Not all directives are supported by Google, however. Google will simply not follow some commands, so being up to date before writing your directives is crucial.
Sitemap
Adding a sitemap to your robots.txt file is an incredibly important tip that shouldn’t be overlooked.
Basically, XML sitemaps give search engines the information you want them to search on your website. With an XML sitemap, search engines can see your relevant pages and the latest updates to your website.
Sitemaps are important because they are among the top searches Google uses to find your page during a search.
Sitemaps can be a powerful tool, so adding your XML site map to your robots.txt page can be very useful.
Unsupported Directives
Since we are on the topic of directives, it is essential to know what directives are unsupported by Google. There are a few directives that are no longer supported by Google or never were. There are instances, however, where Google has an alternative.
The directives that are unsupported by Google are Nofollow, Noindex, Host Directives, and Cawl Delay.
Nofollow
The first unsupported directive is Nofollow directives. These directives were designed to tell user-agents not to follow links to pages and files under the specified page.
The only way to have Google not follow links now is to use a rel= “nofollow” link attribute.
Noindex
Noindex directives are the second directive not supported by Google. This directive allows google to crawl and index your page, but will not include it in search results. There are ways, however, to keep the content on your page hidden.
As an alternative, you may want to use a noindex tag, password protection, or a 404 & 410 HTTP Status Code.
Crawl-Delay
Crawl-Delays are supported by Yandex and Bing, but unfortunately not on Google. Crawl-delays are a directive that tells user-agents to have a delay in time between each crawl.
Host Directive
Yandex only supports this directive, so it’s not the best directive to rely on. However, a 301 redirect of the hostname you don’t want to the one you do want is supported by all platforms.
A host directive allows users to customize whether they want to show “www.” in front of their URL. In practice, it looks like this:
Host: example.com.
Related Link: How to Set up a NGINX 301 Redirect
Disallow Directive
Disallow directives are exactly how they sound. They do not allow search engines to access pages of your website that are labeled as such. Google supports these directives, but they can be a little tricky.
Disallows can be deceiving because they do not work with links to that page. Google can still find them from outbound links. If, for some reason, those outbound links make Google want to add it as a results page, it will regardless of it being disallowed to crawl your page.
For pages containing sensitive information, or pages you really don’t want on search results, disallows may not be the best option.
Best Practices
Use User Agents Only Once
Using and user-agent only once is a good rule of thumb, mainly so the user doesn’t make any mistakes. Google will automatically combine all the directives no matter how many times the user-agent it listed. However, if you get confused with all of the listings, it can be costly. The best practice would be to list your user-agent, then put all the commands you want to apply below that entry.
Use “$” to show the end of URL
Use “$” at the end of URL’s. It’s a helpful tool to let Google know which URL’s can’t be crawled or indexed. For example:
User-agent: *
Disallow: /*.jpg$
This means Google will be disallowed to crawl or index any URL’s ending in “.jpg.” However, that does not mean Google cannot find “.jpg?id=123.”
Write out specifically which URLs you want to be blocked.
Each Directive On A New Line
When you are writing your robots.txt file, make sure you are not crowding the lines with information. Each directive must be located on a new line. This will avoid confusion for the search engines and will prevent any unwanted mistakes.
Be Specific
Specificity is key to avoiding mistakes. The smallest detail can have significant impacts on your SEO. Making sure you close off all entries with a “/” to make sure it doesn’t affect similar pages or using the “$” to close off URL’s can save you from future issues.
Staying organized during any major changes to your website is very important for maintaining the SEO on your page.
Related Links: Website Migration Checklist: SEO Best Practices
Simplify Instructions with Wildcards
Wildcards can save a ton of time and confusion. Using this “*” is the perfect way to make writing you robots.txt files fast and easy. Wildcards are basically the “select-all” option when it comes to user-agents. However, the same can be applied to URLs as well! For example:
User-agent: *
Disallow: /photos/*?
Use Comments to Explain Yourself
If you are writing a robots.txt file for someone else, or you’re nervous you may forget exactly why you put something where you did, leaving comments is an acceptable way to explain why you wrote the section the way you did. Just write “#” then your explanation on a separate line, and you’re good to go. Crawlers will ignore anything that is preceded with a “#.”
Each Sub-Domain Gets it’s Own
Unfortunately, you can’t combine robot.txt files on the sub-domain of your website. For example, if you are the owner of example.com, but you have all of your photography at photos.example.com, these will need separate robot.txt files.
Don’t Block Good Content
As you are editing your robot.txt files, make sure you are not unwillingly blocking good content. It can easily happen with a misspell or just a general oversite. So make sure to check and double-check your files! Driving traffic to your website is the goal, and good content is what does that.
Case Sensitivity
Take note; case-sensitivity exists within robots.txt files. If your file has the wrong capitalization, search engines will not follow the directives you have set for it. A good rule of thumb is to create the file as soon as you can to avoid mistakes. Another good practice you be to try always to use lower case letters. That way, it won’t be hard to remember which capital letter goes where.
Don’t Overuse Crawl-Delay
Crawl-delays can be useful in making sure your site isn’t crowded. However, there is a way to overuse this directive. If you have a large or growing site, having a delay can cost you some valuable searches. Just be aware that in the future, it can cost you organic traffic and ranking.
Check for Errors
As you have seen, it is relatively easy for mistakes to happen with robots.txt files. You will want to check that everything is running smoothly periodically, and thankfully there is a pretty easy way to do that. Using Google’s Seach Console, in the ‘Coverage” report, you will be able to find errors and address them.
Error: Submitted URL Blocked by robots.txt
If you see this error, that means you there are parts of your sitemap that are blocked by robots.txt files. This can happen if redirected, noindexed, or canonicalized pages are included in the sitemap.
The easiest way to find and resolve the issue is to use Google’s robots.txt tester.
Error: Blocked by robots.txt
An error saying “blocked by robots.txt error” means there is a page on your website that is blocked but has not yet been indexed by Google. You can remove the block if this information is important, and you want it indexed. If the page is intentionally blocked, you can use a robots meta tag or an x-robots header to remove the error and keep the content hidden.
Error: Indexed, though blocked by robots.txt
This error indicates that Google still indexed some of the content that is blocked. This has a similar solution to the previous issue. Removing the crawl block and using a meta tag or x-robots header is the best solution if you still don’t want it indexed. Or, if it was unintentional, remove the block to restore visibility.
Conclusion
Learning the in’s and out’s of robots.txt can elevate how your website is crawled by search engines. It takes some getting used to, and the errors can be consequential. But if you take the time to learn, there is no doubt that your SEO can have very positive changes.
You may also like



.png)



An error has occurred somewhere and it is not possible to submit the form. Please try again later or contact us.